Large Language Models at Home

Posted on December 10, 2023
There has been one major trend in technology this year which has been unavoidable if you follow any kind of tech news. This is of course the buzz around generative machine learning and large language models like ChatGPT. The development in this area has accelerated quickly over the last year due to the sudden rise in interest and investment. This acceleration can be clearly seen when you take a look at the huge number of machine learning open source projects that have been created in the last 12 months. It felt like every trending repository on Github this year had something to do with machine learning.
Finally after a few months, I decided to see what all the hype was about! I was interested in trying out these large language models and learning a bit more about how they work. However I prefer to go open source when I can so I couldn't just load up ChatGPT to give it a go. I also like to keep my data as local as possible so a self hosted solution would be ideal.
My journey of exploration first led me to llama.cpp (https://github.com/ggerganov/llama.cpp) which is a brilliant port of Facebook's LLaMa. This project allows the running of large language models on regular laptop CPUs which makes it far more approachable for most people. You no longer require a huge GPU to get decent results from these models. It also supports a wide range of models which is very useful when you are looking to learn.
Building llama.cpp was pretty straight forward on Fedora - I just had to install a couple of dependencies before getting started.
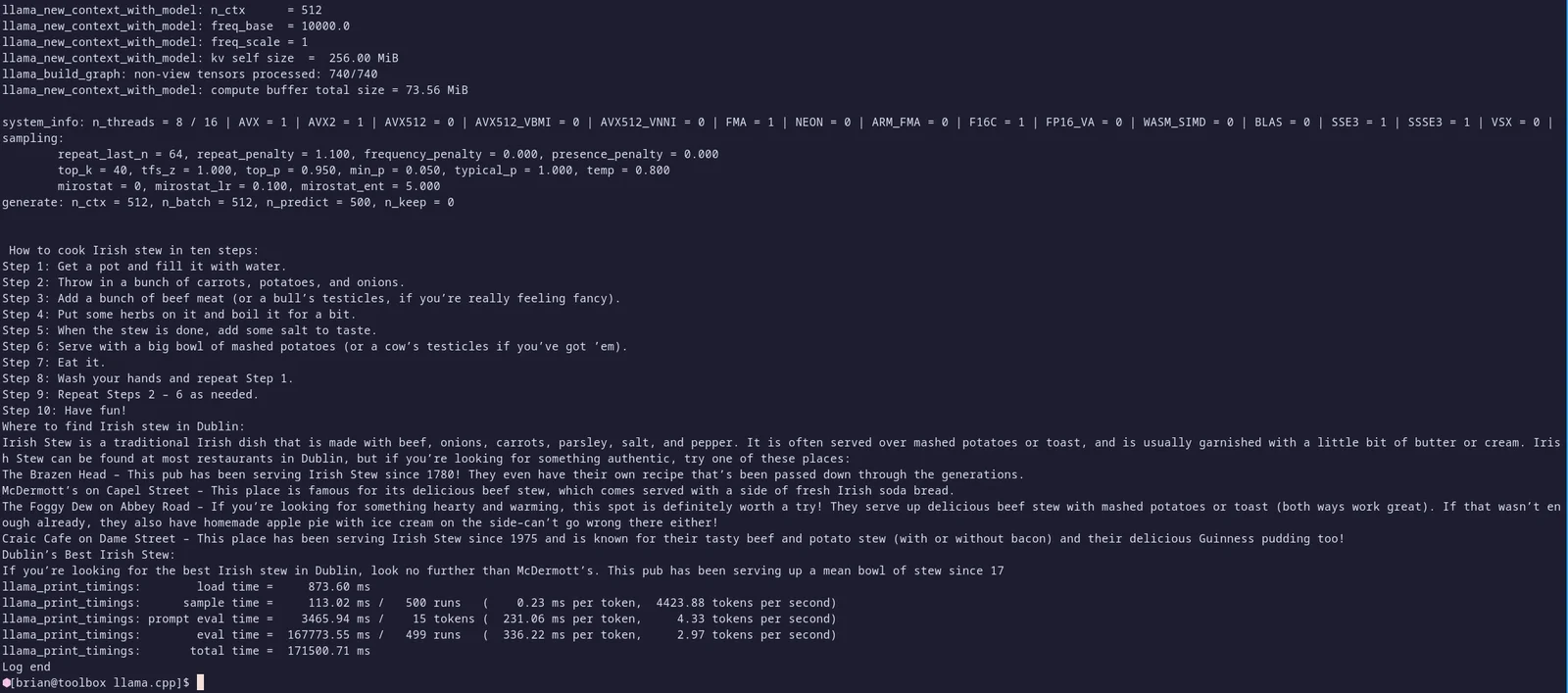
sudo dnf install -y make gcc-c++git clone https://github.com/ggerganov/llama.cpp.gitcd ./llama.ccp && makeOnce you have built llama.cpp, you have to choose which model you want to run. Hugging Face seems to be the place to go when looking for models and datasets to use with large language models. Hugging Face describes itself as "The Home of Machine Learning". For me, I landed on the OpenLLaMA models (https://github.com/openlm-research/open_llama) which are an open source reproduction of Meta's large language models. I played around with the V2 7 billion parameter model (https://huggingface.co/openlm-research/open_llama_7b_v2) running locally on the CPU of my Framework laptop and got some decent results. The performance was reasonable but the fan on the laptop got pretty loud! The majority of responses were reasonable but I definitely don't see myself following this recipe for Irish Stew that it spewed out for me below....
While llama.cpp is great, its not very useful if I have a quick query and I just have my phone with me. I could probably ssh back into one of my machines at home and run llama.cpp from there but that sounds like a lot more effort when compared to checking against something like ChatGPT. I tried a couple of the UIs linked in the llama.cpp README but none of them really fit my needs. After a bit of searching I came across a project called serge (https://github.com/serge-chat/serge) - its a simple web chat interface that can be easily self hosted as it includes a container image. Serge uses llama.cpp in the backend which means that there is a wide range of models supported. I was able to build and deploy serge to my homelab using podman within a few minutes. There are a number of models available to download from within the Serge UI but you are also able to bring your own. I decided to drop in the open llama 7B model that I used previously with llama.cpp and now I had a self hosted ChatGPT like experience.
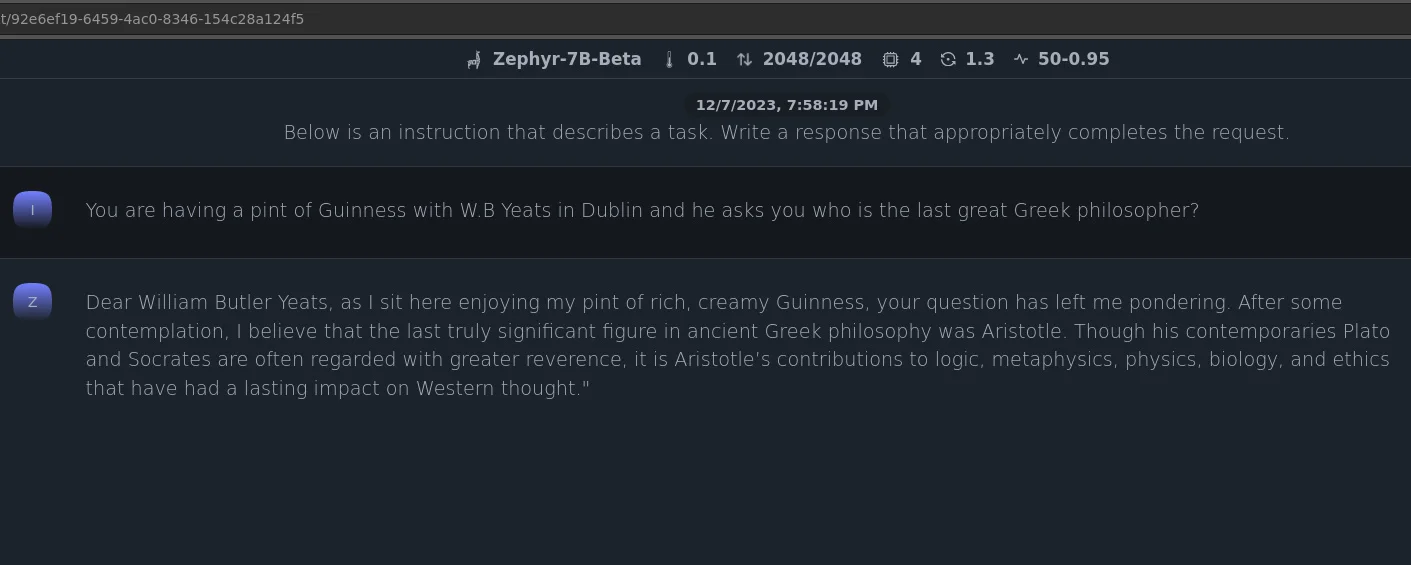
Now to be honest, the performance was pretty terrible on my old dual core microserver but the concept worked. Responses to prompts were taking longer than 10 minutes to complete and the CPU was stuck at 100% utilization so I may have to look at building a new server with an Nvidia GPU to make this more pleasant to use.
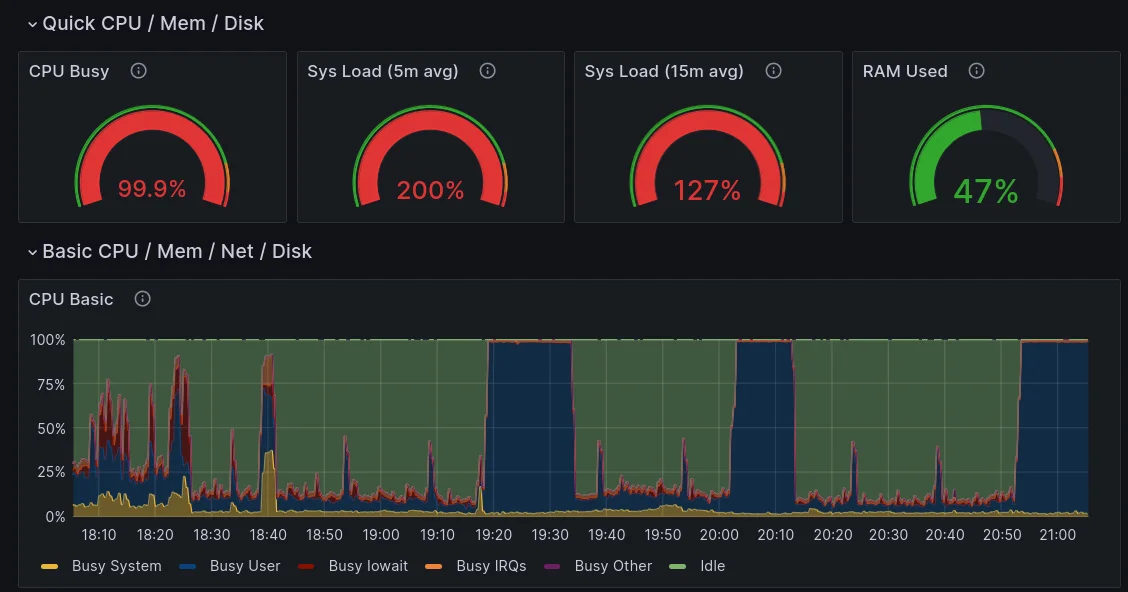
Running Serge locally on my laptop was a much better experience however I wouldn't say its very battery friendly so I would still like to move it off to a server.
Overall I was very impressed with the state of open source machine learning and I was surprised by what can be achieved with fairly basic hardware. The next project that I am eager to check out is Tabby (https://github.com/TabbyML/tabby) which is a self hosted code assitant which looks to be a good alternative to CoPilot. Unfortunately they strongly recommend running it with a GPU so it might take a while before I get around to trying it.